【ポケモンAI】モンテカルロCFRでナッシュ均衡を求める
続き。
前回はpoke_envという対戦シミュレーションライブラリと、CFR(Counterfactual Regret)というアルゴリズムを組み合わせて、1v1シングルバトルにおける最善手を計算してみた。
前回時点では手始めに片側プレイヤー視点での最善手のみ計算したが、今回はいよいよ双方向での計算を行う(行った)。つまり、両プレイヤーがお互いに戦略を最適化しながら均衡解を求める。ゲーム理論の用語でナッシュ均衡という。
今回の対戦メンツはこちらである。

ローブシン Lv.100 @命の珠
てつのこぶし
いじっぱり
H252 D252 S4
・れいとうパンチ
・まもる

フェローチェ Lv.100 @命の珠
ビーストブースト
いじっぱり
A252 S252 D4
・みがわり
・とんぼ返り
・どくづき
(ダメージ計算)
・アームハンマー 80.8 ~ 100.0 %
・れいとうパンチ 85.5 ~ 100.7 %
・マッハパンチ 33.9 ~ 39.9 %
・とびひざげり 80.0 ~ 94.2 %
今回はお互い単純に最大ダメージの技が最善手になってしまうと面白くないので、少し複雑な対面にした。攻撃技・まもる vs とびひざげり・みがわり の読み合い要素がある。
| れいとうパンチ | まもる | |
| とびひざげり | ○(先制で大ダメージ) | ✕ (HP -50%) |
| みがわり | ✕ (HP -25%) | ○(身代わりを残せる) |
つまりお互いの最善手は、相手の行動に左右されることになる。必勝法は存在しない。このような局面において、CFRアルゴリズムが直近の相手の戦略に応じて最適な戦略を計算し、いずれ収束(均衡)に至るかどうか、試した。
やったこと
シミュレーション対戦のルール設定:
(Pokemon Showdownの[Gen 8 1v1]ルールを使用)
・第8世代環境
・1vs1シングルバトル
・ダイマックスは禁止
・お互いレベル100
モンテカルロCFRの設定 (太字は前回からの変更点)
・両プレイヤーで後悔の計算、戦略の更新を行う
・探索率=0.6
・100000回の繰り返し
・情報集合はshowdownサーバーから送られてくる対戦メッセージをそのまま使用する
結果1: 繰り返しごとの勝率推移
最終的な戦略だけ見ても人間も正解はわからないし、「本当に学習しているのか?」という疑問があったので、勝率計算をしてとりあえず計算がうまくいっていることを確認した。
プレイヤー1、プレイヤー2それぞれ、以下のような仮想プレイヤーと戦わせて勝率を計算している。
- ランダムにコマンド選択するプレイヤー(RandomPlayer) →図の青線
- 最大ダメージの技のみを選択するプレイヤー(MaxDamagePlayer) →図のオレンジ線
プレイヤー1 (ローブシン)
最終的に勝率9割程度まで到達。ダメ計を見るとわかるが、とびひざも大抵は珠ダメ込で耐えるので、素直にれいパン→マッパと打てば仮想プレイヤーには勝てる。

プレイヤー2 (フェローチェ)
最終勝率はMaxDamagePlayerで8割程度。
とびひざげりの命中不安があるので、9割以上は厳しいかもしれない。

プレイヤー1とプレイヤー2のどちらも、とりあえず単純な思考をする仮想プレイヤーに対して圧勝できるほどの能力は得られたことがわかった。
プレイヤー1とプレイヤー2の直接対決 (P1の勝率)
後述の戦略と合わせて見てほしいが、定期的に逆転しあっている。それでも若干P1(ローブシン)が有利なようである。
これもCFRにおいてお互いに戦略を最適化しあっていることの一つの証拠となりそうである。

結果2: 初手の戦略
前回同様に、100000回の繰り返しによって学習を行った両プレイヤーの、初手の戦略を確認する。ここでいう戦略とは各技の選択確率のことであり、どの技を選択するかは確率的に決定する。
P1 (ローブシン)
学習初期ではフェローチェのとびひざを潰す、守るを選択している。フェローチェ側がとびひざを選択しなくなると、単にダメージを稼ぐアムハンかれいパンを採用するようになる。(2つの違いはあまり学習できていない)

P2 (フェローチェ)
とびひざは守られるリスクがあるので、早々に選択確率が降下している。とりあえず身代わりで相手の珠ダメを稼ぐ戦法に落ち着いている。

結果3: 各ターンの詳細な戦略
続いて初手以外の戦略について、各ターンごとに分類して結果を記す。
なお、CFRにおいて戦略は、ゲーム木の中で情報集合ごとに蓄積・更新されている。情報集合とはそのプレイヤーが知り得る情報をグループ化したもので、ポケモンの場合であれば自分と相手の選択した行動や、急所などの確率的要素が異なるたびに、別の情報集合にたどり着いて新たに戦略を蓄積することになる。
膨大な情報集合からなるゲーム木の全体を表現することはできないので、今回は代表的な(出現回数の多い)情報集合を取り上げ、それをもとに各ターンのだいたいの戦略を記述することにする。
今回、最終(繰り返し100000回)時点では次のような流れでゲームが展開されていくことがわかった。
- ターン1: フェローチェは珠ダメを稼ぐために身代わりを選択。ローブシンは身代わりを割るためにアムハンorれいパンを選択。
- ターン2: ターン1と同様、身代わりと珠ダメージによるHP減少が行われる。
- ターン3: ローブシンはフェローチェがとびひざげりを打つことを期待して、守るを選択する。フェローチェはとびひざげり①か身代わり②を確率的に選択する。
- ターン4①: フェローチェはとびひざげりの反動ダメージでHPが極小になっているので、ローブシンがマッハパンチを打ってP1の勝ち。
- ターン4②: ローブシンはとびひざげりを防ぐまもるを打つことができず、身代わりの残ったフェローチェを一撃で倒すこともできず、P2の勝ち。

続いて各ターン(に代表される情報集合)の戦略のグラフを記す。
ターン1
(初手の戦略と同様)

ターン2
ローブシン側には若干アームハンマーとれいとうパンチのせめぎ合いがあるが、概ね図に示した通りの戦略。

ターン3
おそらくこのターンが今回の対面では一番重要。P2戦略でとびひざげり(青線)と身代わり(オレンジ線)が拮抗しているので、実際にどちらが選択されるかは、運次第である。
現時点ではとびひざげりの選択確率が若干高く、そのためローブシン側もとびひざげりに有利なように、まもる(赤線)を選択するような戦略になっている。
ちなみにまもるに対しては身代わりが有効だが、万が一この3回目の身代わりが割られると次のマッハパンチを耐えられない(33.9 ~ 39.9 % ダメージ)ので、フェローチェとしてもここで勝負を決めないといけないターンだったと思われる。

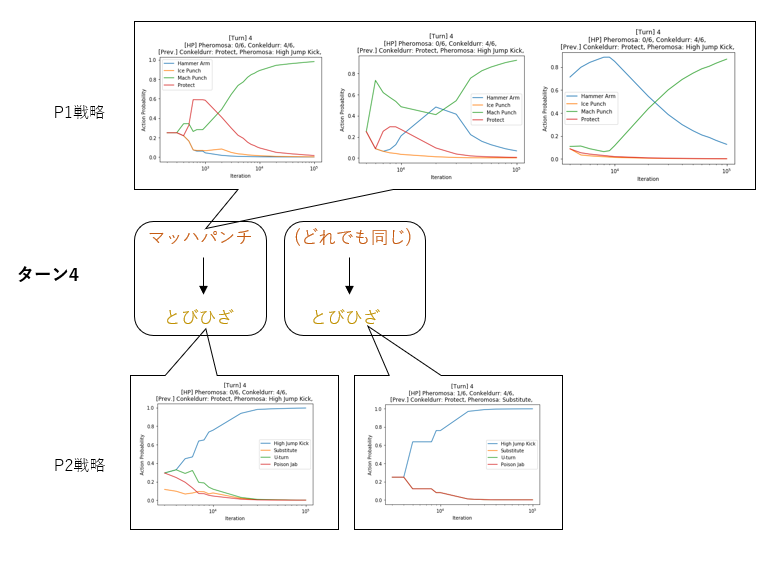
ターン4
HPの少ないフェローチェを確殺するマッハパンチ(緑線)、および珠ダメの入ったローブシンをピッタリ倒す、とびひざげり(青線)がきれいに選択されている。
結果4: 戦略の経時変化
繰り返し計算中のP1vsP2の勝率グラフを再度ご覧いただきたい。
繰り返し回数10^3ほどで、P1の勝率が大きく落ち込んでいる箇所がある。

これを考察するために、先程の詳細戦略(ターン3)のグラフで同じく10^3時点の戦略を見てみる。すると、この時点ではまだローブシン側のまもるの選択確率が低いことがわかる。

ここから繰り返し10^3=1000回時点でのだいたいの戦略を推測すると以下のようになる。つまり、フェローチェが珠ダメ2回+とびひざげりでローブシンをちょうど落とせると発見したところで、ローブシン側はその新しい戦略に対応してきれていない。結果としてとびひざげりをダイレクトに食らえばその時点でP2の勝利である。

100000回の繰り返し計算の中で、両プレイヤーの(均衡)戦略は以下のように推移していったと考えられる。
なお100000回は繰り返し回数としては少ない方で、この先もまた新たな戦略が発見されるかも?
考察・まとめ・感想
本文中に大体書いてしまった
ハッピー節分
【ポケモンAI】モンテカルロ法で"後悔"を学習する
たとえば次の2体のポケモンが1vs1でタイマン勝負をするとする。
ローブシン Lv.100 @くろおび
てつのこぶし
しんちょう
H252 D252 S4
・れいとうパンチ
・こらえる
ビーストブースト
いじっぱり
A252 S252 D4
・とんぼ返り
・どくづき
ローブシン側にはどのターンでどの技を打つかという戦略が存在する。
これをコンピュータで計算するには??という記事。
結果だけ見る場合は下までスクロールしてください。
後悔(Regret)とは
ゲーム理論での用語になります。
参考文献[1]で紹介されている簡単な例だけ紹介したい。
(設定)
AくんとBくんがじゃんけんを連続でプレイする。
Aくんは勝ったら+1、負けたら-1点の得点がもらえ、得点が多いほど嬉しい。
~1戦目~
Aくん: グー、Bくん: パー
Aくんの負け (-1 点)
Aくんはこの試合を振り返って、
「チョキを出していたら勝っていたのになあ…」 とチョキを出さなかったことを激しく"後悔"した。一方でパーに対しては
「パーを出していたらあいこには持ち込めたなあ…」と少しだけ"後悔"した。
グーは実際に出している手なので後悔しなかった。
Aくんは「次はなるべくチョキを出そう」と決心した。
~2戦目~
Aくん: チョキ、Bくん: グー
Aくんの負け (-1 点)
Aくんは前の反省を生かしてチョキを出したが、相手の手が変わったのでまた負けてしまった。この試合を振り返って
「パーを出していったら勝っていたのになあ…」と激しく後悔し、
「グーを出していたらあいこだったなあ…」と少しだけ後悔した。
そして、「1戦目の結果と総合すると、パーを出しておけばあまり後悔しなさそうだ」と推理した。
注) 理想プレイヤーのじゃんけんではこのように計算しても結局グー・チョキ・パーを1/3ずつ出す戦略に落ち着きます。ただ、Bくんに「グーを出すのが好き」などのクセがある場合、そのクセに対応した非対称な戦略が求まるはずです。
説明:
戦略型ゲームの結果から「その行動を取っていたら改善できた利得の量」を後悔(regret)と定義し、
(その行動を取っていた場合の利得) - (実際の利得) でそれぞれ計算する。
この"後悔"を使って、以下の繰り返し計算で最適な混合戦略※1を求めることができる。
・均等な行動確率を初期値に設定
・後悔を0に設定
・行動確率にしたがってゲームを実行
・ゲーム結果から各行動の後悔を積算
・後悔に比例する行動確率を再計算※2
・行動確率にしたがってゲームを実行
・ゲーム結果から各行動の後悔を積算
… 繰り返し
さらに、上のゲームではAくんのみがこの方法を使用していたが、両プレイヤーが同時にこの繰り返し計算を行うと、最終的な戦略がナッシュ均衡(※3)に収束する と証明されている。Regret Matchingという。
※1 確率的に行動を決定する戦略。(例) グーを1/3の確率で出し、チョキを2/3の確率で出す
※2 たとえば下の表の結果では
1戦目終了時に(グー, チョキ, パー) = (0, 2/3, 1/3)、
2戦目終了時に(グー, チョキ, パー) = (1/6, 2/6, 3/6)
と更新される。
※3 お互いに相手の(混合)戦略がわかっていても、自分の戦略(の利得の期待値)を改善する余地が存在しない状態。

実際には最後に更新された行動確率ではなく、各繰り返し中で使用した行動確率の平均(→平均戦略)を最終的な戦略とする。
しかし、ポケモンのようにターン経過があり、終了までのターン数も行動結果によって異なるゲームの場合はどうすればいいだろうか?
そのような一般的な不完全情報ゲームに適用できる手法が、CFR(Counterfactual Regret)である。
正確な情報は参考文献[2]を参照されたい。
プログラムでの実装はこちらのブログと
こちらのリポジトリが参考になった。
終端ノードの利得を到達確率で減衰させながら前方ノードに伝搬させたりしている。ちょっと機械学習っぽさがある。
ゲームの結果を振り返って、「あそこはあの行動を取ってたら有利だったな」と後悔し続ける手法であることは変わりない。
上記のRegret Matchingをポケモン対戦に適用しようとしたとき、いくつか困ることがある。
(1) 特定の局面で行動を変えたときのゲームの結果は、同じ相手(の戦略)と同じ局面を再現できないとわからない。そしてこれは以下の理由で難しい。
- 普通の対戦相手なら、毎回同じ戦略で行動してくれる保証はない
- 技外し・追加効果・ダメージなどの確率的要素をすべて同一に再現するのは難しい
(2) 行動を変えたときのゲームの結果には確率的要素・非公開情報により膨大な分岐がある。
- これはゲームの情報集合※4の多さに由来している。言い換えると以下のようなゲーム木を完璧に作成できて、それぞれの終端の評価値を全部埋められれば理想。しかし、相手の持ち物、持っている技、特性、、、など想定しうるゲームの局面をすべてあらかじめ列挙しておくというのはほぼ不可能なので、現実的ではない。
そのため、実際には「とりあえずゲームをプレイしてみて、分かってる範囲の情報でCFRを行う」手法が必要であるが、そのときに用いられるのがモンテカルロ法である。(モンテカルロCFRと呼ばれる。)
説明は割愛するが、今回は参考文献[3]の中のOutcome Samplingというやつを使った。
※4 ゲーム理論で不完全情報ゲームを取り扱うとき、確率的な要素(プレイヤーに隠されている相手の情報も含む)はChanceプレイヤーという仮想的なプレイヤーの選択の結果として表現する。こうすると、プレイヤーからは区別できない複数のノードがゲーム木上に存在することになり、これをグループ化したものを情報集合と呼ぶ。この定義より、同じ情報集合に属するノードでは同じ行動を選択しなければならない。

poke_env
showdownクライアントとしてのWebsocket実装を強化学習用にラップしたようなもので、基本はローカルでshowdownサーバーを建てて一緒に使う。
ゲームの状態と勝敗からとりあえずディープラーニングする感じの強化学習ならすぐできます。うまく学習できた人が居るのかは知りません。
ゲーム理論的なパラメータはいくつか欠けていたので独自にサブクラスを作って頑張っているのだが、可能性を感じるライブラリなので、余力があったら別記事で紹介したい。
やったこと
冒頭に出したローブシンvsフェローチェ対面の後悔を計算してみた。
シミュレーション対戦のルール設定など
(Pokemon Showdownの[Gen 8 1v1]ルールを使用)
・第8世代環境
・1vs1シングルバトル
・ダイマックスは禁止
・お互いレベル100
CFRアルゴリズムの設定
・ローブシン側プレイヤーのみ後悔・戦略の更新を行う
・探索率=0.4 として、各ターンで40%の確率でランダム戦略を使用する
・1000回の繰り返し
・情報集合はshowdownサーバーから送られてくる対戦メッセージをそのまま使用する※
※ showdownサーバーからは以下のメッセージが各ターンに送られてくるが、これにはそのターンでの各プレイヤーの行動・行動結果としてプレイヤーに見えるゲームの状態がすべて含まれているので、これを蓄積したものをそのまま情報集合として利用できる(今のところは、一致判定さえできればいいので)
ただし、ダメージ乱数によるHPの増減で情報集合がいちいち分かれると学習効率が悪いので、HP表記の部分(自ポケは絶対値表示、相手ポケは%表示)だけ0/6 ~ 6/6 までの簡易的な割合表記に置き換えている
|move|p2a: Swampert|Power-Up Punch|p1a: Conkeldurr
|-damage|p1a: Conkeldurr|372/414 5/6
|-boost|p2a: Swampert|atk|1
|move|p1a: Conkeldurr|Hammer Arm|p2a: Swampert
|-damage|p2a: Swampert|50/100 3/6
|-unboost|p1a: Conkeldurr|spe|1
ダメージ計算など
結果の理解のためにダメージ計算を載せておきましょう。
※レベル100なので普段のダメージ感覚とは違うかもしれません
・アームハンマー 78.4 ~ 92.2 %
・れいとうパンチ 78.4 ~92.6 %
・マッハパンチ 31.4 ~ 37.1 %
・とびひざげり 61.6 ~ 72.5 %
結果(後悔に基づいた最終的な最適戦略)
局面1: 初手
予想: アムハンかれいパン
結果:
・明らかに悪手なマッパとこらえるは早々に選択確率が0になっている
・ダメージ量がほぼ同じなアムハンとれいパンはどっちがいいか迷い続けている。

局面2: 以下の行動の後の2ターン目
予想: 1回こらえても悪くはないが、マッパでいい
結果: きれいにマッパを選択している。

局面3: 以下の行動の後の2ターン目
予想: マッパで普通に落とせるが、ローブシンのHPはまだ満タン(飛び膝1回耐える)なので別にこらえる以外ならなんでもいい
結果:
・マッパ。

局面4: 以下の行動からの2ターン目
予想: マッパ1択
結果:
・れいパンになっているが、うまく計算されていない
・グラフの変化点が少ないため、試行回数が少なかった(この局面があまり発生しなかった)模様。
・ここを計算するには探索率を考慮する必要あり

まとめ
・だいたいうまく計算できている
・違いが分かりづらい技や、あまり発生しない局面は試行回数が足りなくなりがち(探索率の設定の難しさ)
次回(予定)
相手の戦略も変化させる(本来のCFR)と本当にナッシュ均衡に収束するか?
募集
おもしろい対面
参考文献
[1] Neller, Todd W., and Marc Lanctot. "An introduction to counterfactual regret minimization." Proceedings of Model AI Assignments, The Fourth Symposium on Educational Advances in Artificial Intelligence (EAAI-2013). Vol. 11. 2013.
[2] Zinkevich, Martin, et al. "Regret minimization in games with incomplete information." Advances in neural information processing systems. 2008.
[3] Lanctot, Marc, et al. "Monte Carlo sampling for regret minimization in extensive games." Advances in neural information processing systems 22 (2009): 1078-1086.
シングルバトルの選出アルゴリズムを考えよう(2)
(3)有利対面数法
計算手順:
(1)自分PT(6匹)と相手PT(6匹)のポケモンごとの相性を表す対面相性値表を用意する。
(2)自分PTの中から3匹を選出として選ぶ。
(3)選出された3匹について、各相手ポケモンに対して対面相性値が0より大きい(→有利対面)かどうかを表すテーブルを新たにつくる。(分かりやすくするため)
(4)各相手ポケモンごとに、自分の選出ポケモンの中に有利対面をとるものが存在すればTRUE、しなければFALSEを割り当てる。
(5)相手ポケモン6匹のうち、手順(4)でTRUEとなった割合をカバー率と定義する。
(6)手順(3)で作ったテーブルに存在する有利対面の総数を有利対面数と定義する。
(7)すべての自分の選出(20通り)について以上を計算する。
(8)カバー率が最大(大抵は1.0)となる選出のうち、有利対面数の多い選出を採用する。

感想:
相手ポケモンの対策に穴を作らない範囲で、有利対面の数が多い選出を選ぶ。対面相性値(現状は-1024~1024)を簡略化して各対面が「有利」か「不利」かだけを考えている。
おそらく、対面構築の理論にはかなりハマっている。対面構築が想定している、相手倒す→相手死にだし→自分倒される→自分死に出し→相手倒す→… の一直線のフローにおいては、役割対象とはつねにHP満タン状態で対峙することになる。これは対面相性値の計算条件と同じ。そして、つねに相手ポケモンに対して有利なポケモンを死に出しできるかが重要なので、期待値的には、対面相性値から抽出した有利対面の数が多い選出が強くなる。(すべて理想的なケースでの話です)
ただし、特定の相手ポケモンに全く何もできない(穴がある)選出をしてしまうと、もしそのポケモンを繰り出されたとき容赦なく3タテされてしまうし、普通の相手ならそのような"刺さっている"ポケモンはほぼ出してくるので、手順のところに記載した「カバー率」という最低基準を設けている。
どんな選出でもカバー率が1.0にならない相手PTの場合、カバーできなかったポケモンを出されるとほぼ負けだが、出されないことを祈ってとりあえず有利対面数が多い選出を選ぶしかない。ただ、そもそもカバー率 < 1.0 が頻繁にでるような場合、一度PT構築を見直したほうがいいともいえる。
主な課題点:
・「有利」か「不利」かの境界線を対面相性値=0におくと、ある特定ポケモンの処理をギリギリ勝てる程度のポケモンに一任するような選出が出てくる。リスクを考えると対面相性値100か200あたりを境界線にしたほうがよさそう
・たとえば有効対面数が同じ9となる選出でも、内訳を考えると(6, 2, 1)という1匹が全抜きできそうなケース、(3, 3, 3)というどのポケモンも対等に貢献しているケースがあるがどっちがいいのか?
サンプル計算結果
自分: マリルリ・ハッサム・サザンドラ・カビゴン・ローブシン・ヒートロトム
相手: パッチラゴン・ヒヒダルマ(スカーフ)・トリトドン・オーロンゲ・ハピナス・ウーラオス
同じ条件の他の選出アルゴリズム(過去記事)と比較すると面白いかも。強い選出はどのアルゴリズムでも上位にきます。
最適選出: マリルリ・ハッサム・サザンドラ (評価値1105)
次善選出: マリルリ・サザンドラ・ヒートロトム (評価値1095)
※評価値の計算式は適当なので大小だけ注目してください

最適選出 内訳:

次善選出 内訳:

体感では、結構勝てます。
AI使ってどのアルゴリズムが強いのか実証実験したいですね