イタリアから帰ります
こんにちは、イタリア在住系ポケモンAI系モトブロガーのがりゅうです。
約2年間のイタリア生活を終えて日本に帰ることになりました。
ポケモンAI系の記事で僕を知った方もちらほら居ると思うので、改めて今までの僕の状況を説明すると、俗に言う海外赴任という形で2年間イタリアの子会社に在籍していました。
国籍も変わらないし戸籍(住民登録ではない)は残るのですが、日本の住民票がなくなります。住民税を払わなくてよくなります。運転免許証はなぜかイタリアで没収されるきまりなので日本で再発行しないといけません。
イタリアに来る日本人は芸術・飲食・アパレル関係の人が大半なので、ソフトウェアエンジニアとしてイタリアに来ているという僕の理由は自己紹介の時点でかなり変人感がありました。ソフトウェアなら、普通はカリフォルニアとかに行くと思います。
イタリアはいい国です。日本のアニメやゲームも大抵はヨーロッパの都市をモデルにしていたりするので、旅行好きでない僕でも街の雰囲気や景色には圧倒されました(今は慣れた)。ARIAというイタリアのベネチア舞台のアニメがあるそうなのですが、いつか見てみたいと思います。ただリアルなベネチアは狭くて物価が高いだけの離島なのであんなにかわいい女の子は15歳ぐらいで家出すると思います。
あと料理がうまい。毎週宅配ピザを頼んでいます。
イタリア人もいい人です。全体的におしゃべり好きなので頼んでなくても勝手に喋ってるイメージがあります。見るからに外国人の僕にも道を聞いてきたりするのでそれは謎です。(最近はスリの手口か!?と警戒しています)。
まあ、奔放的に生きてる感じがするのでスーパーの店員とかの、ローテンション状態のイタリア人は別に優しくありません。
他にもいろいろありますがコロナウイルスも蔓延してる中、日本以外の国で色々な経験を積めたのはよかったと思っています。一番学んだことは、世の中には知らないことがたくさんあって、自分が知ってることはその中のほんの少しでしかないということかもしれません。
アディオス!
【ポケモンAI】Python製ポケモン強化学習ライブラリ「poke_env」のインストール
対象読者:
目次
- Pythonのインストール
- Showdown サーバーのローカル起動
- Visual Studio Code でのPython環境設定
- poke-env モジュールのインストール
- サンプルコードの実行確認 - ランダムプレイヤー
- サンプルコードの実行確認 - 最大ダメージプレイヤー
- まとめ
前回記事でPokemon Showdownのライブラリ機能について紹介しましたが、今回はさらにポケモンAI開発に特化した最新のPythonライブラリ(インターフェイス)を紹介します。以下のようなことができます。
- 場の状態に応じて行動を決定する(※)"Player"を定義し、Player同士を自動対戦させて結果を収集
- 強化学習用のOpenAI Gym 形式でのPlayerの定義、および対戦実行・学習
- 上記のPlayerを実際のshowdownサーバーで自動的に戦わせる
※ これがいわゆるルールベースAI
僕は強化学習ではなくこの記事にあるようなCFRを実行するためにこのpoke_envを使用しているのですが、共通するインストール方法だけ紹介しておこうかと思います。(ので、強化学習機能の中身についてはまだ触れていません…)
今回も初心者向け解説です。
Pythonのインストール
poke-env はpython 3.6 以上が必要です。
既にインストールされているか調べる
既にPythonがインストールされている場合もあると思います。一例ですが、以下の場合は既にインストール済みです。
powershell(※1) 上で
python -Vと入力してバージョン番号が表示される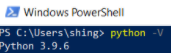
(AnacondaでPythonをインストールした場合) Anaconda Prompt(※2) 上で
python -Vと入力してバージョン番号が表示される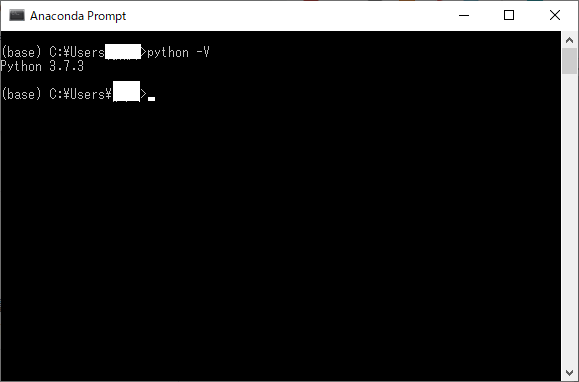
バージョン番号が3.6 以上の場合
-> Pythonに関してはインストールの必要はありません。
バージョン番号が3.6 未満の場合
-> アップデートする必要があります。(当記事では説明しませんが、別途Pythonのインストール関係の情報を参考ください)
※1 Powershell はWindows標準のシェル(コマンドプロンプトの新しい版のようなもの)です。以降よく使います。

※2 Anaconda は科学計算用のモジュールをセットにしたPythonの仮想環境で、Anaconda Promptはその方式でインストールしたPythonを使うために用います。Anacondaと検索して以下のように色々インストールされていたら、過去にAnacondaでPythonを導入しているはずです。

Pythonの新規インストール
新規でインストールする場合は公式サイトのインストーラーからインストールできます。
Downloads > Download for Windows をクリックするとインストーラーがダウンロードできると思います。
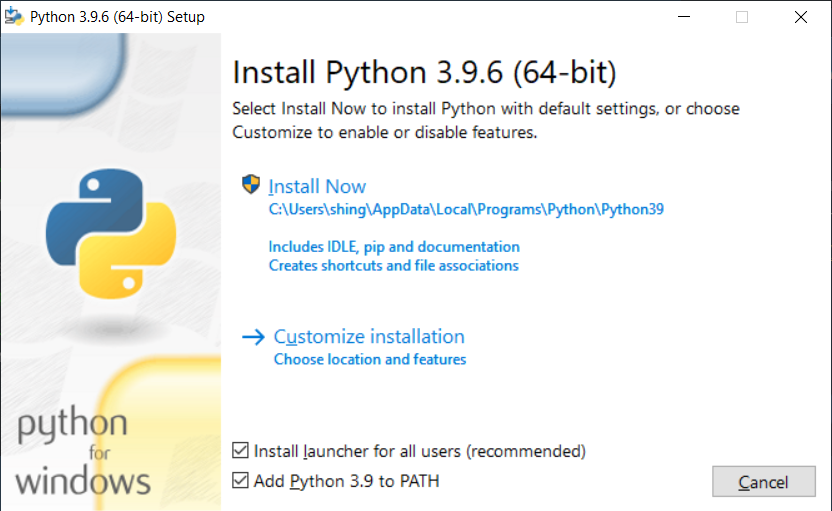
あとはインストーラーを起動してそのままOKボタンを押して進めていくのですが、"Add Python 3.9 to PATH" にチェックを入れておくことをオススメします。

最終的にpython 3.6以上のインストールが確認できればOKです。
なおpoke-envモジュールのインストールにpipというパッケージマネージャも必要になりますが、python 3.4 以降であれば標準装備のはずなので、基本的は問題ないはずです。

Showdown サーバーのローカル起動
poke-envはshowdownサーバーに接続して評価用の対戦を実行します。
Githubで公開されているソースコードを、ローカルPC内にダウンロード or Cloneしてください。 方法は問いません。
- git clone (powershellから) でClone
- SourceTreeなどGUIからClone
- GithubからZipファイルを直接DL

ソースコードがローカルで開けるようになったら、ディレクトリ直下でPowershellを開き、次のコマンドを実行します。
※Node.js のインストールが必要です。前回記事参考のこと。
node pokemon-showdown start --no-security

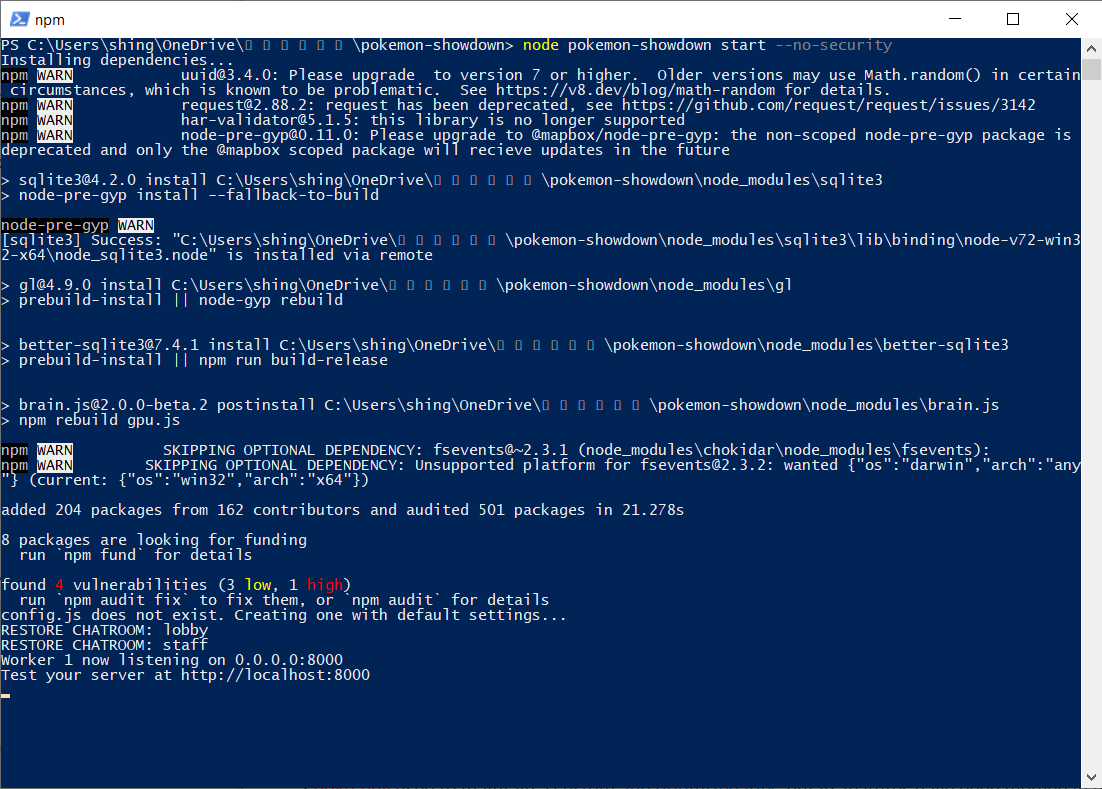
初回は依存関係の解決が行われて追加モジュールが色々DLされると思います。最終的に"Test your server at http://localhost:8000"と表示されれば成功です。 これでローカルPC内の他のプログラムから、ポート8000を通してshowdownサーバーにアクセスできるようになりました。 以降poke-env を使う際には、毎回このようにshowdownサーバーを別途立ち上げておく必要があります。
Visual Studio Code でのPython環境設定
Python の実行環境についてはなんでもいいのですが、説明の都合上VSCodeで行うことにします。
Python 用エクステンションをインストールしておいてください。
Python用エクステンションをインストールしたVSCodeで、適当なフォルダを開きます。このフォルダ内にpoke-envを利用するソースコードを書いていきます。
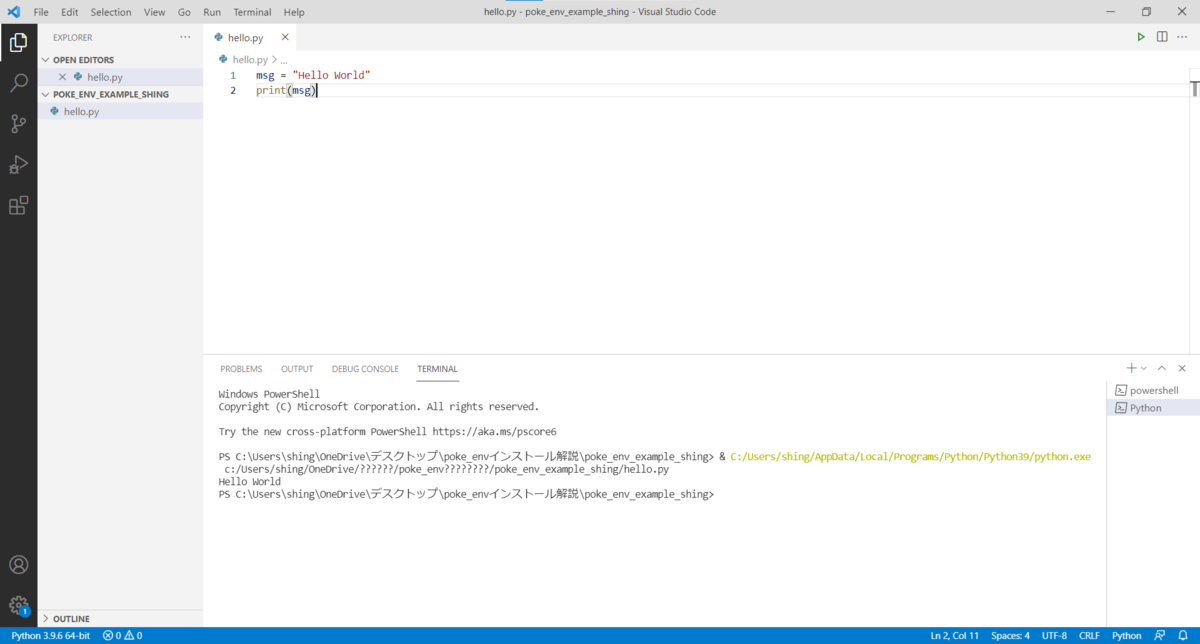
少し省いた説明になりますが、以下の手順でサンプルコードを実行できることを確認してください。
- hello.pyというファイルを作成
- 下記のソースコードをhello.py に貼り付け
- 画面左下にPythonインタプリタの選択画面が出てくるので、冒頭でインストールしたPythonのバージョンと一致しているか確認(※)
- 合っていなかったら、クリックして正しいものに変更する
- 右上の三角ボタンを押してhello.pyを実行
- コンソールにHello worldと表示されれば成功!
msg = "Hello World" print(msg)

※Anacondaなど色々Pythonをインストールしている人は、正確にインタプリタを設定する必要があります。

poke-env モジュールのインストール
Powershellで(※)以下のコマンドを実行します。
pip install poke-env
pip install tabulate
※ VSCodeのコンソールからだとエラーになります
このうちtabulateについてはpoke_envの実行には直接必要ではありませんが、サンプルコードを動かすのに必要となります。ただ、この記事に沿ってPython 3.6 以上の環境で進めている場合は、基本的にインストール済みと表示されると思います。

最後にこのコード実行してみて、特にエラーが表示されなければ環境設定は完了です。 このコードはasyncioという非同期処理ライブラリの基本機能を試しているだけのコードになりますが、特定のIDEの特定の環境設定(※)だとイベントループの生成に失敗して下記のようなエラーが出ることがあります。
"RuntimeError: This event loop is already running"
# -*- coding: utf-8 -*- import asyncio async def main(): pass if __name__ == "__main__": asyncio.get_event_loop().run_until_complete(main())
※ 筆者はSpyderでこのエラー表示を確認しました
サンプルコードの実行確認 - ランダムプレイヤー
参考: Cross evaluating random players — Poke-env documentation
まずは、とりあえずこのコードを実行してみましょう。
# -*- coding: utf-8 -*- import asyncio from poke_env.player.random_player import RandomPlayer from poke_env.player.utils import cross_evaluate from tabulate import tabulate async def main(): # ランダム行動をするPlayerオブジェクトを3個作成します players = [RandomPlayer(max_concurrent_battles=10) for _ in range(3)] # 相互に対戦させ評価を行います。Player同士の一つの組合わせごとに、20回の対戦を行います。 cross_evaluation = await cross_evaluate(players, n_challenges=20) # 表示用のヘッダー行を作成します table = [["-"] + [p.username for p in players]] # 対戦結果を抽出して、それぞれのPlayerごとに1行ずつtableオブジェクトに追加していきます for p_1, results in cross_evaluation.items(): table.append([p_1] + [cross_evaluation[p_1][p_2] for p_2 in results]) # 見やすい表形式で結果を表示します print(tabulate(table)) if __name__ == "__main__": asyncio.get_event_loop().run_until_complete(main())
WARNINGが大量に出ていますが気にしないでください。正常です。
別途立ち上げておいたshowdownサーバー上で行われた、ランダムプレイヤー3人の総当り戦の結果が表示されました! ランダム行動をするプレイヤー同士(ポケモンもランダム)なので、当然どの組み合わせも勝率が0.5付近になっているはずです。

poke-envの仕組み
ここでpoke-envの仕組みについて少し解説します。
poke-envはライブラリを使用するユーザー(例としてAI開発者)が技選択や戦略の学習のロジックを埋め込むインターフェイスを、"Player"というクラスで抽象化しています。
Playerクラスで宣言されているメソッドの中でもっとも代表的なものが、choose_move(self, battle)です。Playerを実際にテスト対戦に用いるときには、技選択がリクエストされる度にこのメソッドが呼ばれます。
そこで、AI開発者は、自分だけの対戦AIの定義として、Playerクラスを継承したサブクラスを作ります。そして「その対戦AIは対戦の局面(battle)が与えられたときに、どのような行動を取るか?」というロジックをchoose_move(self, battle)の実装として表現します(単純なルールベースAIの場合)。実装が終わったら、poke-envに元々組み込まれている対戦実行や結果集計の便利なメソッドから性能評価を行います。
対戦実行メソッドの内部では、showdownサーバーへのwebsocket通信や、並列で対戦を実行するためのスレッド管理などが行われていますが、AI開発者はその内容を気にせずPlayerのロジックの記述だけに集中することができます。
ということで、上のコードで用いられている組み込みのRandomPlayerの定義は以下のようなものになっています。
class RandomPlayer(Player): def choose_move(self, battle) -> BattleOrder: return self.choose_random_move(battle)
強化学習用機能(EnvPlayer)
上記での説明は単純なルールベースAIに限ったもので、実際には、強化学習用の機能が存在します(というか、これが目的でみんな使っています)。具体的にいうと、EnvPlayer という強化学習用のPlayerクラスが存在します。
- Player
- EnvPlayer
- TrainablePlayer
EnvPlayerにはstepというメソッドの宣言があります。これはOpenAI Gym の形式に則ったもので、このEnvPlayerオブジェクトを強化学習におけるEnvironmentとして外部から使用することを想定しています。
step(self, action: int) -> Tuple
筆者は残念ながら強化学習の知識に乏しいのでまだこの機能を試せていませんが、公式マニュアルにはkeras-rlと連携して戦略の学習を行う例があります。参考にしてみてください。
サンプルコードの実行確認 - 最大ダメージプレイヤー
参考: Creating a simple max damage player — Poke-env documentation
以下はサンプルコードの2つ目ですが、いわば「AI開発者が実装したルールベースAIの例」です。
# -*- coding: utf-8 -*- import asyncio import time from poke_env.player.player import Player from poke_env.player.random_player import RandomPlayer class MaxDamagePlayer(Player): def choose_move(self, battle): # playerが一つでも攻撃技を使用可能なときは、攻撃する if battle.available_moves: # 使用可能な技の中で、技威力が一番高いものを探す best_move = max(battle.available_moves, key=lambda move: move.base_power) return self.create_order(best_move) # 攻撃技を使えない場合は、ランダムに控えポケモンと交代する else: return self.choose_random_move(battle) async def main(): start = time.time() # Playerオブジェクトを2つ作成 random_player = RandomPlayer(battle_format="gen8randombattle") max_damage_player = MaxDamagePlayer(battle_format="gen8randombattle") # Playerを評価 (max_damage_player vs random_player の対戦を100回実行) await max_damage_player.battle_against(random_player, n_battles=100) print( "Max damage player won %d / 100 battles [this took %f seconds]" % (max_damage_player.n_won_battles, time.time() - start) ) if __name__ == "__main__": asyncio.get_event_loop().run_until_complete(main())

Max damage player won 88 / 100 battles [this took 31.858377 seconds]
ちゃんとランダムプレイヤーには88%の確率で勝利していますね。
まとめ
今回はインストール方法とサンプルコードの実行確認だけですが、ここから独自のPlayerサブクラスを定義して色々なことができます。 メインの強化学習機能もいつか試します。
正式名称がpoke_env なのかpoke-envなのか謎
Pokemon Showdown のシミュレーターをポケモン対戦ライブラリとして使う
想定読者: プログラミングを学習したことがある人
Pokemon Showdown! という非公式の対戦シミュレーターがあります。

このWebアプリケーションのソースコードはGithubで公開されており(オープンソース)、誰でも閲覧、貢献(プルリクエストの送信)ができます。大きく分けると、以下の2つです。
- サーバー (対戦受付サーバー、対戦シミュレーター)
- クライアント(WebサイトのHTML, CSSなど※)
※詳しく言うと、preactというReact系のフレームワークを使用したシングルページアプリケーションの模様
このうちサーバーの方には、シミュレーター機能を単体でライブラリとして使用するためのAPIが実装されています。内訳は以下の通りです。
JavaScript用ライブラリ
・対戦シミュレーター…(a)
・Teamテキストの変換API
標準入出力経由(→言語不問)で操作するコマンドラインツール
・対戦シミュレーター
・Teamテキストの変換ツール
参考:
https://github.com/smogon/pokemon-showdown/blob/master/sim/README.md
https://github.com/smogon/pokemon-showdown/blob/master/COMMANDLINE.md
今回は、(a)のJavaScript用対戦シミュレーターライブラリを使用してみることにします。初心者向け解説になっています。
サンプルコードはこちらにあるので、使用例だけ見たい方はこちら。
Node.jsのインストール
Node.jsは、サーバーサイドJavaScriptと呼ばれるJavaScriptの実行環境になります。
JavaScriptは通常、Webブラウザを使って、HTMLから呼び出して実行するスクリプト言語ですが、それを通常のプログラミング言語と同様に、ローカルPCやサーバー内でも動かせるようにしたものです。
Pokemon ShowdownのサーバーソースコードはこのNode.jsで書かれているので、ローカルで実行するためにはインストールが必要になります。
Pythonのように、スクリプト言語を一つPCにインストールするようなものだと思っておけばいいです。
Windowsの場合、インストーラーから簡単にインストールできるので、とりあえずLTSバージョンをDL→インストールしておけばいいでしょう。
Visual Studio Code のインストール
単に便利というだけで強制はしないのですが、ここから先はVisual Studio Code(以下VS Code)の使用をオススメします。(説明の上ではVS Codeを使っている前提で進めます)。
VS Codeは非常に高機能なテキストエディタです。厳密にはVisual studio (Codeでない方)、EclipseのようなIDEではないのですが、IDEだと思っても特に不都合はありません。
特にNode.js開発の場合、頻繁にターミナル(コマンドプロンプト)を使うので、ターミナルウィンドウ付きのVS Codeが便利です。
テスト用Node.jsアプリケーションの作成
適当な空フォルダを作って、そのフォルダをVS Codeで開きます。上メニュー>ターミナル>新しいターミナル からターミナルウィンドウも開いておきましょう。
ターミナルに以下のように入力し、Enterを押します。
npm init -y
package.jsonというNode.jsアプリケーション用の設定ファイルが作成されます。

次に、メインプログラムを記述するapp.js (名前はなんでも大丈夫です)を作成しておきます。そして以下のテストコードを入力します。
console.log('Hello world!!')

ターミナルに以下のように入力して実行します。すぐ下の行に"Hello world!!"と表示されれば成功です。ここまででうまくいかなかった場合は、Node.js、VS Codeのインストール、場合によってはPowershellやファイルの操作権限の問題を疑ってください。
node app.js

Showdown JavaScript用ライブラリの使用
参考:
https://github.com/smogon/pokemon-showdown/blob/master/sim/SIMULATOR.md
続いてターミナルで以下のコマンドを実行します。
npm install pokemon-showdown
これによりpokemon-showdown(サーバー)のソースコードがnode_modulesフォルダ内にDLされて、自作のコードから参照できるようになります。package.jsonが更新され、package-lock.jsonというファイルが新規作成されます。
これはnpmというパッケージマネージャの機能です(詳細は省きます)。node_modulesフォルダはpackage.jsonをもとにいつでも復元できるものなので、ソースコードをバージョン管理などするときにこのフォルダを含める必要はありません。

説明ページ(上記)にある以下のサンプルコードを動かしてみましょう。app.js内に貼り付けて、同様にnode app.jsで実行します。
const Sim = require('pokemon-showdown');
stream = new Sim.BattleStream();
(async () => {
for await (const output of stream) {
console.log(output);
}
})();
stream.write(`>start {"formatid":"gen7randombattle"}`);
stream.write(`>player p1 {"name":"Alice"}`);
stream.write(`>player p2 {"name":"Bob"}`);
ターミナル出力に以下のような表示が現れれば成功です!7世代ランダムバトル(※)というルールで、対戦インスタンスが作成され、無事1ターン目がスタートしていることが確認できました。
※ シングルバトル、7世代、6vs6、パーティーポケモンはランダムに決定される

対戦ルールの指定、行動選択の指定、、など上のコードをカスタマイズしていくための知識を少し解説します。
BattleStreamの基本
対戦シミュレーターのインターフェイスは、Sim.BattleStreamクラスで定義されたストリームオブジェクト(※)です。
・ストリームへの書き込みをstream.write()で行い、…(1)
・ストリームからのメッセージはstreamオブジェクト自体をasync iterables オブジェクトとみなして取得できます。…(2)
※ Node.js純正のものではなく、独自実装のようです
(1)で書き込むもの
・対戦の初期化
・行動選択
(1)の基本
・送信コマンドの先頭には">"をつける
・> 以降の内容はコマンド種類による
(1)で書き込む内容の例
>start {"formatid":"gen7ou"}
>player p1 {"name":"Alice","team":"insert packed team here"}
>player p2 {"name":"Bob","team":"insert packed team here"}
>p1 team 123456
>p2 team 123456
(2)で取得できるもの
・対戦メッセージ(HP、ターン数など)
・行動選択リクエスト
(2)の基本
・通知種別?→対戦メッセージの順に改行で区切られて送信される。
・対戦メッセージの中身はさらに"|" で区切られ、メッセージ種類→メッセージに応じた内容 と続く。
(2)の例
update
|
|t:|1625406405
|move|p2a: Jolteon|Thunderbolt|p1a: Dialga
|-resisted|p1a: Dialga
|split|p1
|-damage|p1a: Dialga|193/270
|-damage|p1a: Dialga|72/100
...
上記でわかるように、(1)(2)ともにテキストで表現される独自のメッセージフォーマット(protocol)を把握する必要があります。これらは概ね以下のページで説明されています。
https://github.com/smogon/pokemon-showdown/blob/master/sim/SIM-PROTOCOL.md
今回の記事ではこのうち行動選択場面での要点のみを解説し、あとはサンプルコードの掲載で雰囲気を感じ取ってもらうことを想定しています。
行動選択
参考:
https://github.com/smogon/pokemon-showdown/blob/master/sim/SIM-PROTOCOL.md#choice-requests
行動選択のきっかけは、|request|で始まる以下のような行動選択リクエストの受信です。
sideupdate
p2
|request|{"active":[{"moves":[{"move":"Light Screen","id":"lightscreen","pp":48,"maxpp":48,"target":"allySide","disabled":false},{"move":"U-turn","id":"uturn ...
これの|request| 以降のJSONテキストは次のような形をしています。
{
"active": [
{
"moves": [
{
"move": "Light Screen",
"id": "lightscreen",
"pp": 48,
"maxpp": 48,
"target": "allySide",
"disabled": false
},
{
"id": "uturn",
"pp": 32,
"maxpp": 32,
"target": "normal",
"disabled": false
},
{
"move": "Knock Off",
"id": "knockoff",
"pp": 32,
"maxpp": 32,
"target": "normal",
"disabled": false
},
{
"move": "Roost",
"id": "roost",
"pp": 16,
"maxpp": 16,
"target": "self",
"disabled": false
}
]
}
],
"side": {
"name": "Zarel",
"id": "p2",
"pokemon": [
{
"ident": "p2: Ledian",
"details": "Ledian, L83, M",
"condition": "227/227",
"active": true,
"stats": {
"atk": 106,
"def": 131,
"spa": 139,
"spe": 189
},
"moves": [
"lightscreen",
"uturn",
"knockoff",
"roost"
],
"baseAbility": "swarm",
"item": "leftovers",
"pokeball": "pokeball",
"ability": "swarm"
},
{
"ident": "p2: Pyukumuku",
"details": "Pyukumuku, L83, F",
"condition": "227/227",
"active": false,
"stats": {
"atk": 104,
"def": 263,
"spa": 97,
"spe": 56
},
"moves": [
"recover",
"counter",
"lightscreen",
"reflect"
],
"baseAbility": "innardsout",
"item": "lightclay",
"pokeball": "pokeball",
"ability": "innardsout"
},
{
"ident": "p2: Heatmor",
"details": "Heatmor, L83, F",
"condition": "277/277",
"active": false,
"stats": {
"atk": 209,
"def": 157,
"spa": 222,
"spe": 156
},
"moves": [
"fireblast",
"suckerpunch",
"gigadrain",
"focusblast"
],
"baseAbility": "flashfire",
"item": "lifeorb",
"pokeball": "pokeball",
"ability": "flashfire"
},
{
"ident": "p2: Reuniclus",
"details": "Reuniclus, L78, M",
"condition": "300/300",
"active": false,
"stats": {
"atk": 106,
"def": 162,
"spa": 240,
"spe": 92
},
"moves": [
"shadowball",
"recover",
"calmmind",
"psyshock"
],
"baseAbility": "magicguard",
"item": "lifeorb",
"pokeball": "pokeball",
"ability": "magicguard"
},
{
"ident": "p2: Minun",
"details": "Minun, L83, F",
"condition": "235/235",
"active": false,
"stats": {
"atk": 71,
"def": 131,
"spa": 172,
"spe": 205
},
"moves": [
"hiddenpowerice60",
"nastyplot",
"substitute",
"thunderbolt"
],
"baseAbility": "voltabsorb",
"item": "leftovers",
"pokeball": "pokeball",
"ability": "voltabsorb"
},
{
"ident": "p2: Gligar",
"details": "Gligar, L79, M",
"condition": "232/232",
"active": false,
"stats": {
"atk": 164,
"def": 211,
"spa": 101,
"spe": 180
},
"moves": [
"toxic",
"stealthrock",
"roost",
"earthquake"
],
"baseAbility": "hypercutter",
"item": "eviolite",
"pokeball": "pokeball",
"ability": "hypercutter"
}
]
},
"rqid": 3
}
クライアント(今回の自作プログラム)は、このrequestオブジェクトをもとに次の行動をストリームに書き込むことになります。送信コマンドの一例は以下になります。
- >p2 move lightscreen
- >p2 move default
- >p2 switch 2
ただし、上記のrequestオブジェクトの例に含まれていないパターンも多数あり、たとえば以下の状況の際にはrequestオブジェクトに追加の情報が付加されます。関連して送信コマンドに追加のパラメータが必要なケースもあります。この詳細は現状ではマニュアル化されていませんが、いくつかのパターンについては今回のサンプルコード内で実装したので、参考にしてください。
サンプルコード
執筆時点でのapp.jsの中身を貼り付けておきます。今まで同様に手元のapp.jsに貼り付けて実行すると、結果が表示されると思います。
(サンプルコードをGit Clone or ダウンロードした人向けの実行方法:)
npm install
node app.js
NUM_OF_BATTLESの回数だけ8世代ランダムバトルを繰り返して、最後にお互いの勝利数を出力するプログラムになっています。技選択はランダム、死に出し交代先はその時点で先頭のポケモンです。
現実的に対戦AIのようなものを作る場合は、onChoiceRequest関数内に独自の行動選択ロジックを実装していくことになります。
const Sim = require('pokemon-showdown');
stream = new Sim.BattleStream({keepAlive: true}); // 連続で対戦を行うときはkeepAliveオプションが必要
/*********************************************************************
* 対戦インスタンスの設定 (好きな値に調整)
* *******************************************************************/
const NUM_OF_BATTLES = 10;
const battleFormat = {
formatid:"gen8randombattle" // 対戦ルールを表す内部IDを指定
}
const p1 = {
name:"プレイヤー1"
}
const p2 = {
name:"プレイヤー2"
}
/*********************************************************************
* 集計用 (特別な意味はありません)
* *******************************************************************/
let battleCount = 0;
const winCount = {
[p1.name]: 0,
[p2.name]: 0
}
/*********************************************************************
* BattleStream操作用ロジック
* *******************************************************************/
function writeAndLog(command) {
console.log(`>> ${command}`)
stream.write(`>${command}`) // > を先頭につけるのを忘れずに
}
function startNewBattle() {
console.log(`新規の対戦を開始します(${battleCount + 1}回目)…`);
}
function onChoiceRequest(choiceRequest) {
const player = choiceRequest.side.id
if (choiceRequest.forceSwitch) { // 死に出し選択状態
return
return
} else if (choiceRequest.teamPreview) { // 選出選択、一部ルールでは存在
// 選出選択が存在するルールでは適当なロジックを書く
return
} else if (!choiceRequest.active) {
return
}
const availableMoves = choiceRequest.active[0].moves.filter(move => !move.disabled)
const rand = Math.floor(Math.random() * availableMoves.length) // 例としてランダム技選択
const move = availableMoves[rand];
writeAndLog(`${player} move ${move.id}`)
}
function onBattleWin(winnerName) {
console.log(`対戦結果: ${winnerName}の勝ち`)
winCount[winnerName]++
battleCount++
}
// 参考: シミュレータープロトコル
const streamOutputHandler = async () => {
for await (const output of stream) { // cf. async iterables
console.log(`<< ${output}`)
const lines = output.split('\n')
if (lines[0] === 'end') {
if (battleCount < NUM_OF_BATTLES) {
startNewBattle();
} else {
console.log('すべての対戦が終了しました。');
console.log('勝利数:')
console.log(winCount);
}
continue;
}
lines.forEach(line => {
const records = line.split('|')
if (records.length < 2) {
return;
}
switch (records[1]) {
case 'request':
onChoiceRequest(request)
break;
case 'win':
onBattleWin(records[2])
break;
default:
return;
}
});
}
};
streamOutputHandler();
startNewBattle();
次回につづくかもしれない